후속문(Continuation) : 제1부. 개념과 call/cc
이 글은 Loom Project를 소개하면서 다루기로 하고 미루었던 후속문(Continuation)에 대한 글이다. 최근에 동시성 프로그래밍의 복잡성을 해결하는 방법으로 코루틴이나 파이버와 같은 경량 스레드에 대한 요구가 증가하고 있다.[1] 그에 따라 이런 경량 스레드를 구현하는데 사용되는 후속문에 대한 이해가 중요해졌다. 하지만 아직 후속문에 대한 한글 자료가 많지 않은데, 이 글이 도움이 되길 바란다.
1. 후속문 개념잡기
후속문(Continuation)은 프로그램 제어에 관한 추상화 개념이다. 모든 프로그램은 후속문 관점으로 볼 수 있다. if 문은 2가지 후속문 중 선택이며, 예외(Exception)는 후속문을 버리는 것이고, for 문은 후속문의 반복이다. 모든 언어는 후속문을 암묵적으로 사용하고 있지만, 후속문을 일급 객체(First Class)로서 명시적으로 지원하는 언어들은 Lisp나 ML 계열의 일부 비주류 언어들뿐이었다. 하지만 최근에는 Python(Stackless Python), Ruby(Continuation)뿐만 아니라, C++(boost.context.continuation)이나 Java(Loom Project), Javascript(rhino) 등 주류 언어들에서도 후속문을 지원하거나 지원 예정에 있다. 이 글에서는 후속문의 개념에 관해 설명한다.
보통 프로그램이 실행될 때는 현재 실행되고 있는 코드가 프로그래머의 관심의 초점이다. 후속문은 프로그래머의 관심을 현재 실행되고 있는 코드가 아니라 뒤이어 실행될 코드로 옮긴다(마치 주식에서 현물이 아닌 선물을 거래하는 것처럼). 만약 현재 실행되고 있는 코드에 뒤이어서 실행될 코드, 즉 후속문을 프로그래머가 마음대로 결정할 수 있다면, 그것은 바로 프로그램 제어를 마음대로 결정한다는 것을 의미한다. 후속문의 제어가 곧 프로그램의 제어 흐름을 결정하는 것이다.
레일을 까는 것이 곧 기차의 경로이다. |
||

|
||
그로밋이 일급 레일 연장(First-Class continuation of rail)을 깔고 있다. 플라톤의 국가론을 읽었던 그는 Continuation 개념을 탑재했음이 분명하다. |
프로그램에서 제어 흐름을 결정할 때 if, for, while 등의 제어문을 사용한다. 이런 제어문들은 컴파일러에서 기본으로 제공해 주는 것이지만, 만약 후속문이 지원된다면 보다 더 정교하고 다양한 제어 흐름을 프로그래머가 직접 만들어 사용할 수 있다. 예를 들어 map을 순회(iterate)할 때 보통은 map의 끝까지 가야 하나 후속문을 사용하면 조건에 맞는 map의 요소(element)에서 바로 리턴하게 만든다든가, 평가가 끝날 때까지 중간에 리턴할 수가 없는 Lisp 같은 언어에서 평가 중간에 리턴하게 만들 수가 있다. 사실 컴파일러는 if.[4], for, while 같은 문법 요소를 내부적으로는 후속문으로 구현할 수 있다. 이뿐만 아니라 후속문은 예외(Exception), 파이버(Fiber), 코루틴(Coroutine), 제너레이터(Generator), 비결정적 선택(Non-deterministic Choice)과 같은 고급 제어 문법 요소를 구현하는 데도 사용된다. 사실 컴파일러 자체를 후속문을 기반으로 만들기도 한다.(Compiling with Continuations) 이처럼 후속문은 프로그램 제어 흐름에 대한 가장 근본적인 개념을 제공하기 때문에, 프로그래밍 언어에서 후속문을 일급 객체(First-class Entity)로써 제공한다는 것은 곧 컴파일러가 할 수 있는 프로그램 제어 흐름에 대한 모든 능력을 프로그래머에게 제공하는 것이 된다. 즉 일급 객체가 된 후속문은 프로그램 제어에 관한 최상의 도구이다.
1.1. 암묵적 후속문
모든 프로그램은 암묵적 후속문의 관점에서 볼 수 있다. 현재 실행되고 있는 코드 뒤에는 항상 이어서 나오는 코드가 있으니까. 하지만 후속문 관점에서 프로그램을 해석한다는 것은 후속문에 익숙지 않은 프로그래머들에게는 사실 매우 낯설기만 하다. 그래서 아주 간단한 예부터 시작해서 후속문 개념에 익숙해질 필요가 있다.
후속문이라는 개념을 익히기 위해서 모든 프로그램을 임시로 전행문, 현행문, 후행문으로 나누어서 생각해보자. 전행문은 앞서 이미 실행된 코드이고, 현행문은 지금 실행되고 있는 코드이고, 후행문은 바로 뒤에 이어서 실행될 코드라고 하자.
다음 프로그램을 보자.
var a = 10; ; 전행문 (1)
var b = a + 5; ; 현행문 (2)
var c = b + 2; ; 후행문 (3)여기서는 현행문을 라고 정했다. 프로그램을 해석할 때 현행문은 프로그래머가 실제로 실행되고 있는 코드라고 여기면서 현재 그 동작에 관심을 두는 코드라고 보면 된다. 현재 우리는 var b = a + 5 라는 코드에 관심이 있다고 가정했기 때문에 이 코드가 현행문이 되는 것이다. 이 코드 이전 코드는 전행문이고, 그 이후 코드는 후행문이다. 따라서 은 전행문이고, 은 후행문이다. 그리고 후행문은 실행되는 후속문이다. 반면 실행되지 않는 후속문도 있다.
var a = 10; ; 전행문 (1)
if (a > 0) ; 현행문 (2)
console.log("Positive"); ; 후행문 (3)
else
console.log("Negative");여기서는 현행문이 비교문이다. 그리고 후행문은 3 라인이다. 5 라인은 실행되지는 않지만 현행문 뒤에 있으므로 후행문은 아니지만 후속문이다. 후속문은 실행되지 않는 것까지 포함하는 개념이다(프로그램에서 예외를 던지는 경우에서처럼). 즉 5라인은 실행되지 않도록 결정된 후속문이다.
var sum = 0; ; 전행문 (1)
for (var i=0; i<10; i++) { ; 현행문, 후행문 (2)
sum += i; ; 현행문, 후행문 (3)
}여기서 현행문은 for 문이다. for 문은 2개 라인에 걸쳐 있다. 그런데 for 문의 끝에 다다르면 제어가 다시 for 문의 처음으로 가기 때문에 for 문 자체는 또한 후행문이다. 즉 이 경우는 현행문이 후행문이 되는 경우다.
위 3가지 예들을 통해서 프로그램을 후속문의 관점에서 보았다. 위 예들에서 후행문은 후속문이다. 후속문은 실행과는 관계없이 뒤에 이어지는 코드를 말하기 때문에 후행문이 아닌 후속문도 있다.
하지만 위 예제들에서 후속문은 암묵적 상태에 있다. 이 코드들은 그저 작성된 순서대로 실행될 뿐이다. 일단 실행이 되면 이 코드들은 마치 밤하늘에 붙박이처럼 박혀있는 별자리와 같이, 혹은 운명처럼, 그 실행 순서가 정해져 있다. 결코 프로그래머가 그 순서를 동적으로 바꿀 수가 없다. 프로그래머가 동적으로 그 실행 순서를 바꾸고 다루고 조작할 수 있으려면 그것을 실체화하고(reify) 이름을 부여해야 한다. 이 말은 후속문이 일급객체가 되어야 한다는 것이다. 그런데 후속문은 코드이기 때문에 이것이 일급객체가 된다는 것은 곧 함수가 된다는 것이다. 함수는 프로그래머가 다룰 수 있는 개체(entity)이다.
1.2. 후속문의 실체화(Reification of Continuation)
암묵적 후속문은 실체화(reify)되어 프로그래머가 다룰 수 있는 하나의 함수로 만들 수 있다. 프로그래머는 후속문을 함수처럼 다양하게 조작할 수 있다. 즉 호출하거나 혹은 호출하지 않거나, 호출한다면 몇 번이나 할 것인지, 그리고 언제 어디서 호출할 것인지, 또 어딘가에 저장하거나 혹은 전달하거나 등등 . 하지만 프로그램은 실체화 이전이나 이후나 하는 일은 똑같다.
다음 예에서 위의 예제 1. 암묵적 후속문 1을 함수로 실체화하고 있다.
function cont_add_2(x) { c = x + 2; }
var a = 10;
var b = a + 5;
var c;
cont_add_2(b)암묵적 후속문이었던 var c = b + 2를 cont_add_2라는 함수로 실체화하면서 원래 후속문이 있던 자리에서는 cont_add_2함수의 호출로 바뀐다.
다음은 위의 예제 2. 암묵적 후속문 2를 실체화하고 있다.
function cont_then(x) {
console.log("Positive");
}
function cont_else(x) {
console.log("Negative");
}
var a = 10;
if (a > 0)
cont_then();
else
cont_else();암묵적 후속문 2의 비교문에서 then 절의 코드는 cont_then 함수로 else 절의 코드는 cont_else 함수로 각각 이동하면서, 그 자리에는 호출을 남겼다.
다음은 위의 예제 3. 암묵적 후속문 3을 실체화하고 있다.
var sum = 0;
function cont_for(i, last, step) {
sum += i;
if (i < last)
cont_for(i + step, last, step);
}
cont_for(0, 10, 1);암묵적 후속문 3의 for 문을 cont_for라는 재귀함수로 실체화하였다. for 문은 그 자체가 현행문이면서 동시에 후속문이기 때문에 함수가 다시 자신을 호출하는 재귀함수로 구현된 것이다.
위 예제들을 보다 보면 후속문은 함수의 형태이기 때문에 도대체 함수와 어떻게 다른 것인지 궁금해질 것이다. 사실 거의 모든 함수가 후속문이라고 할 수 있다. 왜냐하면, 어떤 함수든 결국 어떤 코드 뒤에서 호출된 것이라고 볼 수 있기 때문이다. 어떤 함수를 그냥 함수로 볼 것인지 아니면 후속문으로 볼 것인지는 결국 관점의 차이이다. 만일 함수를 어떤 일의 뒤에 실행된다는 관점에서 본다면 그 함수는 후속문이 된다. 그래서 용어가 중요한 것이다. 함수를 후속문이라고 부른다면, 그 함수를 어떤 일의 뒤에 실행되는 코드라는 관점에서 보겠다는 것이 된다. 이런 점에서 콜백 함수는 후속문이다. 왜냐하면, 콜백 함수는 어떤 일이 수행된 후에 이 함수를 호출해달라는 표현이기 때문이다.
2. 후속문 프로그래밍
위에서도 언급했지만 후속문을 일급 객체로서 지원하는 언어들은 많다. 그런데 언어마다 후속문을 지원하는 방식은 조금씩 다르다. 마치 어떤 기능(예를 들어 스레드)에 대한 API가 언어마다 다른 것과 같다.
하지만 이런 다름에도 불구하고, 후속문을 일급 객체로서 지원하는 언어들 대부분이 call/cc라는 API를 지원한다. call/cc는 Scheme이라는 언어에서 처음으로 지원되었는데, 이후 다른 언어들에서도 지원하게 되었다. 따라서 후속문 프로그래밍에서 call/cc를 아는 것은 중요하며, 알아두면 그 지식을 다른 언어에서도 유용하게 적용할 수 있다. 또한, 한 단계 발전한 한정 후속문(Delimited Continuation)을 알기 위해서도 먼저 call/cc를 알아둘 필요가 있다. 이 글에서는 Scheme의 방언인 Racket으로 call/cc에 대해 설명을 이어간다.
|
이 글의 call/cc 예제 코드의 실행은 Racket(Scheme의 방언) 언어의 IDE인 DrRacket에서 했다. 독자분들도 DrRacket을 설치하면 별도의 과정이나 수정 없이 예제 코드를 간단히 복사/붙이기 하면 바로 실행해 볼 수 있다[다운로드]. 사실 Racket 언어에는 다양한 한정 후속문(Delimited Continuation)들이 구현되어 있다. 우리가 나중에 살펴볼 한정 후속문인 shift/reset도 Racket 언어로 테스트해 볼 것이다. 첨언하면 Racket 언어를 만든 사람과 한정 후속문 중 하나인 prompt/control을 만든 사람이 같은 사람(Matthias Felleisen)이다. |
2.1. call/cc
call/cc는 call-with-current-continuation의 준말이다. call/cc가 단어 길이가 짧아서 더 많이 쓰인다(Scheme에서는 call-with-current-continuation라는 함수만 있고, Racket에서는 call/cc가 call-with-current-continuation의 alias로 정의되어 있다). 그래서 call/cc는 call-with-current-continuation 라는 이름에서처럼 현후속문(current continuation)을 인자로 해서 호출하기 라는 의미라고 보면 된다. 현후속문이란 이제 방금 실체화되어(reify) 일급 객체가 된 따끈따끈한 후속문이라고 생각하면 되겠다. 사실 일급 객체가 된 후속문은 저장이 가능해서 이미 이전에 실체화된 후속문이 여럿 존재할 수 있기 때문이다.
말을 좀 더 단순하게 하기 위해 인수가 하나인 함수를 '단항 함수’라고 부르겠다. call/cc는 단항 함수를 입력받는 단항 함수다. call/cc가 하는 일은 후속문을 캡처하고, 이 캡처한 후속문을 인자로 해서, 입력받은 단항 함수를 호출하는 것이다. 이 후속문은 call/cc가 호출된 지점에서의 후속문을 캡처한 것이다(call/cc와 같은 후속문 관련 API들이 후속문을 자동으로 실체화하는 것을 '캡처한다'라고 한다). 다시 말해 call/cc는 입력받은 단항 함수를, 캡처한 후속문을 인자로 해서 호출하는 단항 함수이다.
다음은 call/cc의 정의를 가장 간단하게 나타낸 것이다. 아마도 call/cc는 다음과 같이 정의되어 있을 것이다.
(define (call/cc f) (1)
(let ((k .....)) (2)
(f k))) (3)| 1 | call/cc 함수를 정의하고 있다. f는 call/cc의 인수이다. 보다시피 call/cc는 단항함수이다. f도 단항함수이다. |
| 2 | .....는 후속문을 캡처하는 코드를 나타낸다. 이것은 언어 차원에서 캡처를 해주는 것이기 때문에 구체적으로 어떻게 캡처하는지는 모르지만, 어쨌든 캡처된 후속문은 함수가 되어 지역변수 k에 바인딩한다(일반적으로 후속문 함수를 나타내는 변수명은 알파벳 k로 표기한다. 일관성을 위해 이후로 후속문 함수는 k로 나타낸다). |
| 3 | 보다시피 f도 단항함수인데 후속문 k를 인자로 해서 호출한다. 사실 이게 call/cc가 하는 역할의 전부다. |
예제 7의 가상 정의 코드로 call/cc가 하는 일을 정리하면 다음과 같다.
-
단항함수를 인자로 받는다 :
-
후속문을 캡처해서 후속문 함수로 만든다 :
-
의 후속문 함수를 인자로 해서 의 단항함수를 호출한다 :
|
아마도 call/cc의 출력에 대해서는 왜 이야기하지 않는지 궁금한 독자도 있을 것이다. call/cc도 함수이므로 당연히 출력이 있다. 하지만 좀 복잡하다. 사용자 코드(바로 뒤에서 설명한다)에서 후속문 함수를 호출하느냐 아니냐에 따라, 출력이 있는 경우도 있고 없는 경우도 있다. 후속문 함수를 호출하는 경우에 코드의 흐름이 어떻게 되느냐를 파악하는 것이 call/cc 프로그래밍의 관건이며, 바로 이 글의 목적이다. |
다음은 call/cc의 사용법을 보여준다.
(call/cc (1)
(lambda (k) (2)
...k...)) (3)| 1 | call/cc를 호출한다. |
| 2 | 람다 함수를 만들어서 call/cc의 인자로 전달한다. 이 람다 함수를 위의 call/cc의 정의에서 인수 f로 받게 되는데, 이 함수는 call/cc 구현부에서 후속문 함수를 인자로 해서 호출될 것이다. 여기서도 후속문 함수를 받는 변수는 k로 표기한다. |
| 3 | ...k...는 실제 후속문 함수를 사용하는 사용자 코드이다. 사용자 코드에서는 후속문 함수를 저장할 수도 있고, 호출할 수도 있고, 호출하지 않을 수도 있다. |
call/cc는 인자로 받은 단항 함수의 사용자 코드(...k...)를 실행해주는 역할을 한다는 것을 파악하는 것이 중요하다. 단지 그 단항 함수의 사용자 코드에서 후속문 함수를 유저가 사용할 수 있도록 만들어 주고 있을 뿐이다.
|
예제 8의 |
다음은 call/cc의 호출이 결국 사용자 코드의 실행으로 되는 과정을 보여준다.
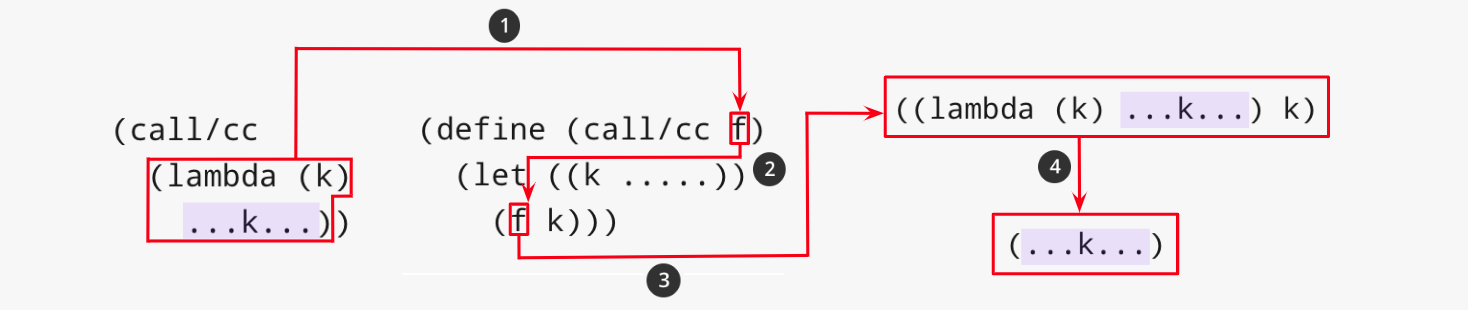
| 1 | call/cc 호출로 람다 함수(왼쪽의 빨간 상자)가 인자가 되어 인수 f에 바인딩된다. 옅은 보라색 사각형은 사용자 코드를 나타낸다. |
| 2 | f를 호출한다. 이때 캡처한 후속문 함수 k가 인자로 람다 함수에 전달된다. |
| 3 | f의 호출은 결국 f에 바인딩된 람다 함수의 호출이다. |
| 4 | 람다 함수의 호출은 람다 함수의 몸체(body)의 코드의 실행이다. 결국, 이것은 call/cc의 사용자 코드의 실행이다. |
지금까지 call/cc에 관해 설명하였는데, call/cc를 사용할 때 중요한 것은 call/cc가 호출될 당시의 후속문이 무엇인지에 대한 파악이다. 즉 사용자 코드에서 사용하게 될 후속문 함수가 어떤 모양새의 함수가 되는지에 대해 프로그래머는 바로 알 수 있어야 한다.
|
영어에서는 후속문과 후속문 함수를 구분하지 않고 통칭해서 Continuation이라고 표현하고 있는데, 이 때문에 때로 혼동을 일으키는 경우도 있다. 이 글에서는 명확하게 하기 위해 후속문과 후속문 함수를 구분한다. |
이를 위해 후속문을 찾는데 쓰는 방법인 v 표기법에 대해 알아보겠다.
2.2. v 표기법
v 표기법[5]은 call/cc의 후속문 함수가 어떤 함수인지를 파악하게 해주는 방법이다. v 표기법은 뒤에서 설명할 v 인자 대입법과 함께 call/cc를 사용하는 코드를 해석하는데 요긴한 코드 해석 기법이다. v 표기법을 사용하면 call/cc의 후속문 함수를 머릿속으로 구성해 낼 수 있는데, 이것이 되어야 call/cc의 사용자 코드가 어떻게 동작하는지에 대한 파악이 가능해진다.
v 표기법은 다음과 같다.
-
현재 코드의 현행문을 정한다.
-
그 현행문을 알파벳 문자 v로 바꾼다.
-
전체 코드를 람다 함수로 감싼다.
다음은 (+ (* 3 4) 5) 코드에 v 표기법을 적용하는 과정을 보여준다.
(+ (* 3 4) 5) ==> (+ v 5) ==> (lambda (v) (+ v 5))위 코드에서는 (* 3 4)를 현행문으로 정했다. 이 현행문을 v로 바꾼다. 그리고 나서 인수 v를 받는 람다 함수 (lambda (v) .....)로 감싼다. 이렇게 해서 만들어진 (lambda (v) (+ v 5)) 이 (* 3 4)를 현행문으로 했을 때의 후속문 함수이다.
현행문 (* 3 4)를 인자로 해서 후속문 함수를 호출하면 원래 코드와 같게 된다. 즉 ((lambda (v) (+ v 5)) (* 3 4))는 원래 코드인 (+ (* 3 4) 5) 와 같다.
다음 코드에서는 3을 현행문으로 보았다.
(+ (* 3 4) 5) ==> (+ (* v 4) 5) ==> (lambda (v) (+ (* v 4) 5))위 코드에서는 현행문 3을 v로 바꾼 후, 역시 인수 v를 받는 람다 함수로 감쌌다.
마찬가지로 현행문 3을 인자로 해서 후속문 함수를 호출하면 원래 코드와 같게 된다. 즉 ((lambda (v) (+ (* v 4) 5)) 3)는 원래 코드인 (+ (* 3 4) 5) 와 같다.
전체 코드를 현행문으로 볼 수도 있는데 그러면 후속문 함수는 identity 함수가 된다.
(+ (* 3 4) 5) ==> v ==> (lambda (v) v)여기서도 다음과 같이 현행문을 인자로 해서 후속문을 호출하면 결국 원래 코드와 같다 : ((lambda (v) v) (+ (* 3 4) 5))
그러면 5를 현행문으로 정하면 후속문 함수는 무엇이 될까? 연습으로 여러분의 머릿속에서 직접 생각해보자.
다음은 (+ (* 3 4) 5) 식의 각 항에 v 표기법을 적용하여 후속문를 구하는 과정을 나타낸다.
| 표현식 | 현행문 | v 축약식 | 후속문 함수 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
v |
|
자 이제 call/cc를 사용해 볼 때가 되었다.
2.3. call/cc 적용하기
지금까지 사용했던 코드 (+ (* 3 4) 5)에 call/cc를 적용해 보자.
다음은 현행문을 (* 3 4)로 정했을 때의 call/cc를 사용한 코드이다.
(+ (call/cc
(lambda (k)
(* 3 4))) (1)
5)
;=> 17| 1 | 사용자 코드에서 후속문 k를 사용하지 않았다. |
위 코드의 결과는 17이다. 위 코드는 다음과 같이 동작한다. 앞서 보았듯이 call/cc는 사용자 코드를 실행하는 것이 전부이다. 그래서 call/cc의 결과는 사용자 코드의 결과이다. 현재 사용자 코드는 (* 3 4)이므로 위의 코드에서의 call/cc는 (* 3 4)의 결과인 12를 리턴한다. call/cc가 12를 리턴했으니 전체 코드는 (+ 12 5)이 되어 최종 결과는 17이 된 것이다.
위의 코드에서는 call/cc에 의해 캡처된 후속문 함수 k를 사용하지 않았다. 다음 예제에서는 사용자 코드에서 후속문 함수 k를 호출한다.
(+ (call/cc
(lambda (k)
(k (* 3 4)))) (1)
5)
;=> 17| 1 | 사용자 코드에서 후속문 함수 k를 호출한다. |
재밌게도 위 코드의 결과도 17이다. 후속문 함수 k를 호출하지 않은 경우와 결과가 같다. 왜일까?
그 이유를 알려면 후속문 함수 k의 중요한 특성인 탈출(espace)에 대해서 알아야 한다.
2.4. 탈출(escape)
call/cc에 의해 캡처된 후속문 함수는 탈출 함수이다. 무슨 말인고 하면, call/cc에서 후속문 함수를 호출하면 그 시점에서의 모든 스택이 풀리면서, 제어는 최상위 코드단으로 이동하고 call/cc를 감싸고 있는 코드는 실행되지 않는다. 마치 예외를 던진 것과 같다.[6] 그래서 사실 위의 코드에서 call/cc 이후의 코드 (+ 5)는 실행되지 않는다. 그런데도 결과가 같은 이유는? 그것은 후속문 함수가 (lambda (v) (+ v 5)) 이기 때문에 여기에 (* 3 4)의 결과인 12를 인자로 호출하면 결국 17이 되기 때문이다. 즉 후속문 함수가 자신이 탈출한 코드와 같기 때문에 같은 결과가 나온 것이다.
(+ (call/cc
(lambda (k)
(+ 3 (k 4)))) (1)
5)
;=> 9| 1 | 사용자 코드에서 후속문 함수 k의 호출이 다른 사용자 코드 (+ 3 .....) 이 수행되기 전에 이루어지고 있다. |
위 예제에서는 후속문 함수 k가 실행되면서 최상위 코드단으로 제어가 이동하기 때문에, 나머지 사용자 코드 (+ 3 .....)은 수행되지 않는다. 위의 경우, 후속문 함수 (lambda (v) (+ v 5))에 인자 4가 적용되어, 결과는 9가 된 것이다.
다음은 후속문 함수가 하위 함수들에서 호출되어도 탈출되는 것을 보여준다.
(define (f2 k) (1)
(println "f2 entered")
(k "continuation")
(println "not printed"))
(define (f1 k) (2)
(println "f1 entered")
(f2 k)
(println "not printed"))
(let ((s (call/cc (3)
(lambda (k)
(begin
(println "called in call/cc")
(f1 k) (4)
(println "not printed"))))))
(println (string-append s " returned"))) (5)
;>> "called in call/cc"
;>> "f1 entered"
;>> "f2 entered"
;>> "continuation returned"| 1 | f2 함수를 정의한다. 인수 k에는 후속문 함수가 들어온다. f2 함수는 이 후속문 함수를 호출한다. |
| 2 | f1 함수를 정의한다. 인수 k에는 후속문 함수가 들어온다. f1 함수는 이 후속문 함수를 호출하지 않고 f2 함수에 전달한다. |
| 3 | 마치 call/cc의 리턴값이 지역 변수 s에 바인딩되는 것으로 보인다. 이때 이 리턴값은 f2 함수에서 후속문 함수를 호출하는데 사용된 인자이다. |
| 4 | 후속문 함수를 인자로 해서 f1 함수를 호출한다. |
| 5 | 후속문 함수가 리턴한 값을 프린트한다. |
위 예제에서 3개의 (println "not printed") 식은 모두 실행되지 않는다.
위 예제에서 후속문 함수는 f1 함수를 거쳐 f2 함수로 전달되어서 f2 함수에서 호출되고 있다. f2 함수에서 후속문 함수가 호출되면 제어는 스택 프레임을 뛰어넘어서 call/cc가 호출되었던 지점으로 이동한다(왜냐하면 call/cc 호출 이후가 바로 후속문이므로). 제어의 이동과 함께, 후속문 함수가 받은 인자 "continuation"이라는 문자열도 call/cc 가 호출되었던 지점으로 전달된다. 그리고나서 이 값이 지역 변수 s에 바인딩된다. 이것은 위 코드상으로만 본다면 마치 call/cc가 그 값을 리턴한 것처럼 보인다(사실은 호출한 것인데). 하지만 위 코드에서 call/cc는 값을 결코 리턴하지 못한다. 왜냐하면 (f1 k) 이후의 코드는 실행되지 않기 때문이다. 마찬가지로 f1 함수와 f2 함수의 마지막 식들은 실행되지 않는다. 후속문 함수가 호출되는 순간, 제어는 call/cc 자리로 이동하기 때문에(그리고 후속문 함수의 인자도), 후속문 함수 호출 이후의 코드들은 실행되지 못한다.
후속문 함수의 이런 특성은 자바나 C++의 throw/catch와 비슷하다. throw/catch처럼 제어가 스택 프레임상의 몇 단계 위로 이동할 수 있는 이러한 특성을 Non-local Exit[7]라고 한다. throw/catch 외에 Non-local Exit 기능을 구현한 것으로는 C언어의 setjmp/longjmp[8]가 있다. 하지만 후속문 함수의 탈출은 Non-local Exit보다는 더 큰 개념이다. Non-local Exit은 한 스택 안에서 제어가 스택 위로 이동하는 것이지만, 후속문 함수의 호출은 별도의 스택으로 대체되는 것이다. 스택을 완전히 대체하는 것이기 때문에 후속문 함수의 호출은 캡처되었던 당시의 모든 지역 변수들이 복원된다. 반면 Non-local Exit은 스택 프레임을 빠져나오면서 일부 지역 변수를 잃어버리게 된다.
후속문 함수의 탈출 대한 이해를 돕기 위해, 예제 9와 예제 10에서 call/cc 호출시 콜 스택의 변화를 비교해 본다. 아래 그림2와 그림 3은 실제의 콜 스택을 나타낸다기보다는 이해를 돕기 위해서 콜 스택에 대한 개념도 수준으로 그려본 것이다. 그림에서 실선 화살표는 호출을, 파선 화살표는 리턴을, 굵은 쇄선 화살표는 후속문 함수의 탈출을 나타낸다.
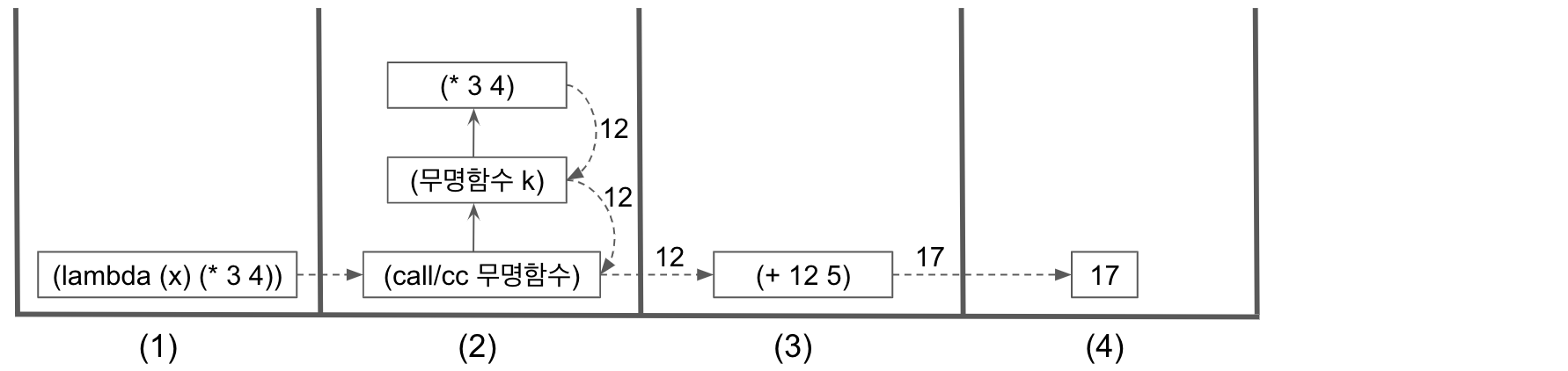
예제 9에서 가장 먼저 실행되는 함수는 (lambda (k) (* 3 4)) 이다. 이 함수가 실행될 때의 콜 스택을 위 그림 2의 (1) 에서 나타내었다. 이 함수는 '무명함수’를 리턴한다. 이 '무명함수’를 인자로 해서 call/cc가 호출된다. call/cc는 인자로 받은 '무명함수’를 호출하고, '무명함수’는 (* 3 4)를 호출한다. * 연산자는 12를 리턴하고, 무명함수도 12를 리턴한다. 여기까지의 콜 스택을 위 그림 2의 (2) 에서 나타내었다. call/cc가 12를 리턴하고 스택을 빠져나가면, (+ 12 5)가 콜 스택에 들어온다. 이제 콜 스택은 위 그림 2의 (3) 의 상태가 된다. (+12 5)는 17을 리턴해서 스택에는 위 그림 2의 (4) 에서처럼 17이 최종값이 된다.
위 그림 2는 call/cc가 호출되더라도 후속문 함수가 호출되지 않는다면, 콜 스택은 일반적인 함수 호출과 같다는 사실을 보여준다.
이제 예제 10에서 후속문 함수가 호출되는 경우, 스택의 변화는 어떻게 되는지 보자.
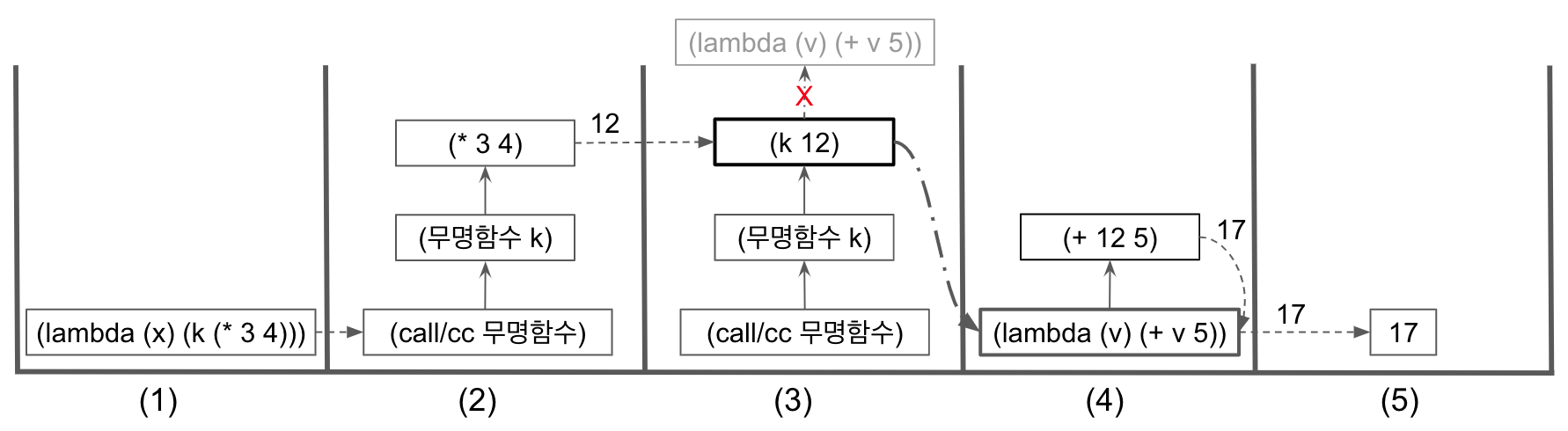
예제 10에서도 가장 먼저 실행되는 함수는 (lambda (k) (k (* 3 4))) 이다. 그리고 (*3 4)가 호출되고 12를 리턴하는 상황까지는 그림 2와 같다. 달라지는 것은 리턴된 12를 받아 후속문 함수 k가 호출된다는 것이다. 그 상황을 위 그림 3의 (3)에서 나타내었다. 그런데 후속문 함수 k가 호출되면 스택에 또 쌓이는 것이 아니라, 스택이 완전히 비워지면서 후속문 함수 k, 즉 (lambda (v) (+ v 4))만 스택에 남게 된다. 이때의 스택의 상태를 위 그림 3의 (4) 에서 나타내었다. 바로 이 지점이 후속문 함수의 탈출을 잘 보여주는 장면이다. 위 그림 3의 (3) 에서 후속문 함수 k가 호출되지만, 후속문 함수의 실제 실행은 그림 3의 (4) 와 같이, 지금까지 쌓였던 모든 스택 프레임을 비우고, 오직 후속문 함수만 스택에 남게 된다. 이후부터는 다시 정상적인 호출이 진행된다. (+ 12 5) 가 호출되면서 스택 프레임이 쌓이고, 17이 리턴되면, 후속문 함수가 받아서 다시 17을 리턴한다. 이제 스택은 위 그림 3의 (5) 에서처럼 17이 최종값으로 남게 된다.
2.5. return문 구현하기
call/cc에 의해 캡처된 후속문 함수의 탈출이라는 이러한 특성을 이용하면, Scheme이나 Racket 같은 리스프 언어에는 없는 return을 구현할 수 있다.
다음은 return을 구현한 아주 간단한 예제이다.
(define (f return) (1)
(return 2)
3)
(f (lambda (x) x))) (2)
;=> 3
(call/cc f) (3)
;=> 2| 1 | return을 인수로 받는 함수 f를 정의한다. return은 함수인데, f 함수 안에서 호출된다. |
| 2 | 함수 f를 identity 함수(입력을 그대로 출력하는 함수)를 인자로 해서 호출한다. |
| 3 | 함수 f를 call/cc로 호출한다. |
위 예제의 에서 함수 f는 identity 함수를 인자로 받아 호출한다. identity 함수는 인자가 되어 함수 f에서 return 인수에 바인딩된다. 식 (return 2)가 호출되면 return은 identity 함수이므로 2를 그대로 리턴하고 버려지며, 마지막 식인 3이 함수 f의 리턴값이 된다.
반면 에서 함수 f는 call/cc의 인자로서 호출되고 있기 때문에, 함수 f의 return 인수에는 후속문 함수가 전달된다. 식 (return 2)가 실행되면 return은 후속문 함수이기 때문에 바로 그 자리에서 제어는 탈출하게 된다. 따라서 아래에 있는 코드 3은 수행되지 않고, 2가 함수 f의 리턴값이 된다.
하지만 위 예제는 별로 유용한 코드는 아니다. 후속문 함수를 이용한 return 사용법을 보여주기 위해 억지로 만든 코드이기 때문이다.
다음은 return을 좀 더 유용한 방식으로 사용한 예제이다.
(define (print-list a-list) (1)
(for-each (lambda (element)
(printf "~a " element))
a-list))
(print-list '(1 2 3 0 4 5)) (2)
;>> 1 2 3 0 4 5
(define (print-list-till-zero a-list) (3)
(call/cc (lambda (return)
(for-each (lambda (element)
(if (= 0 element)
(return (void))
(printf "~a " element)))
a-list))))
(print-list-till-zero '(1 2 3 0 4 5)) (4)
;>> 1 2 3| 1 | print-list 함수를 정의한다. 인수 a-list는 리스트를 받는다. 이 함수는 인수의 요소들을 프린트한다. |
| 2 | 리스트 '(1 2 3 0 4 5)를 인자로 print-list 함수를 호출한다. 1 2 3 0 4 5가 프린트된다. |
| 3 | print-list-till-zero 함수를 정의한다. 인수 a-list는 리스트를 받는다. 이 함수는 print-list 함수와 같이 리스트의 요소들을 프린트한다. 다른 점은 리스트에서 0을 만나면 프린트를 중단한다. |
| 4 | 리스트 '(1 2 3 0 4 5)를 인자로 print-list-till-zero 함수를 호출한다. 1 2 3이 프린트된다. |
for-each는 두 번째 인자로 받은 리스트의 모든 요소를 순회하면서 첫 번째 인자로 받은 함수를 호출한다. 정상적인 경우에 for-each는 리스트의 모든 요소를 순회하게 된다. 그러나 가끔 리스트를 순회하다가 특정 요소에서 중단하고 싶을 때가 있다. 이럴 경우 위와 같이 call/cc를 이용하면 중간에 리턴할 수 있다.
return은 후속문 함수의 탈출을 이용하는 것이기 때문에 for-each 문이 call/cc의 사용자 코드 속으로 들어왔다. 위 코드에서 후속문 함수는 return이라는 의미를 살리기 위해 k가 아니라 return 인수가 받는다. 사용자 코드에서 return을 호출하면 후속문 함수의 호출이기 때문에 전체 사용자 코드를 탈출하게 된다. 이런 식으로 for-each 중간에서 실행을 중단하는 것이 가능하게 되는 것이다.
2.6. 후속문 함수 저장하기
후속문 함수의 진정한 힘은 후속문 함수를 저장할 때 나온다. 저장된 후속문 함수를 필요할 때 다시 호출할 수 있다는 것은 엄청난 파워를 갖는다.
(define *k* #f) (1)
(+ (call/cc
(lambda (k)
(begin
(set! *k* k) (2)
(k (* 3 4)))))
5)
;=> 17
*k* (3)
;=> #<continuation>
(*k* (* 3 4)) (4)
;=> 17
(*k* 1)
;=> 6| 1 | 후속문 함수를 저장하기 위한 전역변수 *k*를 정의한다. (당장은 임시로 불린값(boolean value) #f로 설정한다) |
| 2 | 후속문 함수를 전역변수 *k*에 저장한다. |
| 3 | 전역변수 *k*에 저장한 것은 후속문 함수임을 확인한다. #<continuation>은 후속문 함수임을 보여준다. |
| 4 | 전역변수 *k*에 저장한 후속문 함수를 호출한다. |
위 예제는 후속문 함수를 저장했다가 다시 호출할 수 있음을 보여주고 있다. 전역변수뿐만 아니라 지역변수나 리스트 등에 저장해서 사용할 수도 있다. 후속문 함수가 저장되었다가 나중에 다시 호출될 수 있다는 것은 엄청난 파워를 의미하는데, 이것은 이후 예제를 통해 살펴보게 될 것이다.
2.7. 후속문 이디엄
call/cc를 사용할 때 자주 쓰는 이디엄(Idiom)이 있다. 다음과 같다.
(let ((x (call/cc (lambda (k) k)))) (1) (2)
(x (lambda (ignore) "hi"))) (3)
;=> "hi"| 1 | call/cc의 사용자 코드는 단지 k뿐이므로, 후속문 함수 k를 리턴하기만 한다. |
| 2 | 리턴된 후속문 함수를 지역변수 x에 바인딩한다. |
| 3 | 저장된 후속문 함수를 호출한다. |
위 예제는 call/cc를 사용하는 코드에서 많이 볼 수 있는 이디엄을 아주 간략하게 보여주고 있다. 이후의 예제들에서 call/cc를 적용하는 복잡한 코드를 이해하기 위해서는 이 이디엄을 잘 이해해야 한다. 이 예제가 어떻게 동작하는지 하나씩 분석해보자.
우선 후속문 함수 k는 어떤 모양일지 파악해보자. call/cc 문(즉 (call/cc (lambda (k) k)))의 바깥에 있는 모든 코드가 후속문이다. 예제 16에서 후속문이 되는 코드를 아래에 보라색 바탕의 이탤릭체로 표기하였다.
(let ((x (call/cc (lambda (k) k))))
(x (lambda (ignore) "hi")))이제 v 표기법을 사용해서 call/cc 문을 v로 대체하고, 람다 함수로 랩핑하면, 후속문 함수가 된다.
다음과 같다.
(lambda (v)
(let ((x v))
(x (lambda (ignore) "hi"))))위 코드에서 let 문만 보면 원래 코드(예제 16)에서 call/cc 문을 v로 대체한 게 전부다. call/cc 프로그래밍에 익숙해지면 call/cc 문을 v로 대체해버리는 방식으로 코드를 해석하게 된다(굳이 후속문 함수를 만드는 복잡한 과정 없이, 단순하게 v 표기법으로 코드 해석이 가능해진다).
이제 예제 16의 을 보자. call/cc의 사용자 코드 내부에서 후속문 함수 k를 호출하지 않고 리턴만 했기 때문에 탈출은 없다. 그래서 call/cc는 캡처한 후속문 함수 k를 바로 리턴한다. 리턴된 후속문 함수는 let문에서 변수 x에 바인딩된다. 그러고나서 에서 x에 바인딩된 후속문 함수를 호출하는데, 이때 인자는 (lambda (ignore) "hi")이다. 이 람다 함수를 편의상 '람다 함수 hi’라고 부르자.
후속문 함수의 호출 (x (lambda (ignore) "hi"))에 의해 이제 예제 16은 다음 코드가 된다.
((lambda (v)
(let ((x v))
(x (lambda (ignore) "hi"))))
(lambda (ignore) "hi"))위 코드는 람다 함수 hi를 인자로 해서 후속문 함수를 호출하는 것이다. 이 코드가 실행되면 후속문 함수의 인수 v에 람다 함수 hi가 들어가고 후속문 함수의 본문(body)이 실행된다. 후속문 함수의 본문의 let식에서 v는 람다 함수 hi로 대체된다.
이제 예제 16은 다음 코드가 된다. 이것은 후속문 함수 본문(body)의 실행이다.
(let ((x (lambda (ignore) "hi")))
(x (lambda (ignore) "hi")))이 코드를 보면 원래 코드(예제 16)의 call/cc 자리를 람다 함수 hi로 대체한 것과 같다. 이번에는 let식에서 지역 변수 x에 람다 함수 hi가 바인딩된다. 그리고 다시 x에 바인딩된 함수, 즉 람다 함수 hi가 호출되는데, 이번에는 인자가 람다 함수 hi 자기 자신이 된다.
이제 예제 16은 다음 코드가 된다.
((lambda (ignore) "hi") (lambda (ignore) "hi"))위 코드에서 앞의 람다 함수 hi의 인수 ignore에 뒤의 람다 함수 hi 자기 자신이 들어간다. 그런데 이 람다 함수 hi는 인수를 사용하지 않고 단지 "hi"만을 리턴한다. 이 리턴값이 예제 16의 최종값이다.
2.8. v 인자 대입법
지금까지의 과정을 하나씩 보았는데 좀 복잡해 보일 수 있다. 하지만 실제로는 코드가 어떻게 실행되는지 간단하게 머릿속에서 유추해 볼 수 있다. 원래 코드(예제 16)에 v 표기법과 v 인자 대입법을 차례로 적용하면 된다.
v 인자 대입법[9]은 위에서 설명한 v 표기법과 함께 call/cc를 사용하는 코드를 해석하기 위한 코드 해석 기법이다. v 인자 대입법은 후속문 함수가 호출될 때 적용하는 기법이다. 후속문 함수가 호출되는 과정을 보면, 호출시에 받은 인자가 후속문 함수의 인수 v에 바인딩되고, 이 인자는 후속문 함수 몸체(body)에서 나타나는 v를 대체하게 된다. 이 과정을 짧게 한 것이 v 인자 대입법이다. 즉 v 표기법에 의해 call/cc 문을 v 로 바꾸고, 다시 v를 후속문 함수의 인자로 바꾸는 것이다. 예제 16의 코드에 v 표기법과 v 인자 대입법을 적용해서 코드를 해석하는 과정을 아래에 나타냈다.

| 1 | (1)의 첫째 줄의 call/cc 에 v 표기법을 적용해서 (2)가 된다. 이때 x는 call/cc가 리턴한 후속문 함수로 바인딩된다. |
| 2 | (2)의 둘째 줄에서 x의 호출은 후속문 함수의 호출이 된다. 호출되면서 람다 함수 hi가 인자가 되어, 후속문 함수의 인수에 바인딩된다. 이때 후속문 함수의 코드 속의 v가 아니라, 이 대신에 (2)의 첫째 줄의 v를 둘째 줄의 람다 함수 hi로 대체하고 코드 해석을 v가 있던 자리에서 다시 시작한다. 이것이 v 인자 대입법이다. |
| 3 | v 인자 대입법에 의해 코드는 (2)에서 (3)이 된다. 코드 해석도 v가 대체된 자리에서 다시 시작한다. 그래서 이제 x는 람다 함수 hi에 바인딩된다. |
| 4 | (3)의 둘째 줄의 x의 호출은 람다 함수 hi의 호출이다. 그리고 인자는 람다 함수 hi가 자기 자신이므로, (4)의 코드가 된다. |
위에서 코드 (1)은 예제 16과 같은 코드다. 코드 (1)에 v 표기법을 적용하면 코드 (2)로 바뀐다. 코드 (2)에서 x는 이미 후속문 함수가 바인딩되어 있는 상태이다. 그래서 코드 (2)에서 x의 호출은 후속문 함수의 호출이 된다. 이때 인자는 람다 함수 hi이다. 이 인자가 바로 위에 있는 v 를 대체한다. 이것이 v 인자 대입법이다. 이렇게 해서 코드 (2)는 코드 (3)이 된다. 이제 코드 (3)에서 x에는 람다 함수 hi가 바인딩된다. 결국 코드 (3)은 코드 (4)가 된다.
2.9. 후속문 함수의 호출은 인자가 딸린 GOTO
위에서 v 표기법과 v 인자 대입법이라는 것을 배웠다. 사실 이 두 개를 합치면 후속문 함수 호출은 마치 인자가 딸린 GOTO처럼 해석될 수 있다. 즉 v 표기법은 마치 GOTO문에서 점프할 위치에 라벨을 붙이는 것과 같이 call/cc 자리를 v로 표기하는 것이고, v 인자 대입법은 GOTO의 점프가 해당 라벨로 제어를 옮기는 것처럼, 후속문 함수를 호출하면 제어가 v가 표기된 자리로 점프하는데, 이때 인자도 같이 전달되면서 그 라벨 자리(v로 대체된 call/cc 자리)에 인자가 들어가게 된다. 즉 후속문 호출은 마치 GOTO label argument에서처럼 label위치로 점프하면서 그 label위치에 argument를 전달하는 것과 같은 것이다. 결국, call/cc 자리는 마치 GOTO의 라벨처럼 나중에 제어가 점프하면서 인자가 전달되는 곳이 된다. 후속문 함수가 호출되면 call/cc 자리로 제어가 점프하고 인자도 그 자리로 전달되는 것이다.
후속문이 GOTO라는 관점을 이용하면, 예제 15는 더 간단한 과정으로 해석될 수 있다.

| 1 | 후속문 함수가 호출되면서 제어는 call/cc 자리로 점프하고, 인자는 call/cc 자리로 전달된다. |
| 2 | 람다 함수 hi가 자기 자신을 인자로 해서 호출된다. |
이제 call/cc를 사용하는 좀 더 복잡한 코드를 보자.
다음 예제들에서 저장된 후속문을 다양하게 이용하는 여러 방법에 대해 배운다.
2.10. 음양
다음으로 후속문 이디엄을 사용하는, 간단하면서도 중요한 응용 기법을 보여주는 예제를 볼 것이다. 후속문 프로그래밍을 강력하게 만드는 기법 중 하나가 call/cc로 캡처되는 후속문 속에 call/cc를 두는 기법이다.
(let* ((yin ((lambda (k) (display #\@) k) (call/cc (lambda (k) k)))) (1)
(yang ((lambda (k) (display #\*) k) (call/cc (lambda (k) k))))) (2)
(yin yang)) (3)예제 17은 일명 yin-yang인데, 이것은 후속문을 주제로 하는 컴퓨터 공학 논문에서 자주 다뤄지는 예제이다.[10] yin-yang은 '음양’의 중국식 발음을 영문으로 나타낸 것이다. 위 코드를 실행하면 문자 @와 *가 번갈아 가며 반복해서 무한히 찍힌다. 반복시마다 @는 한 번만 찍히지만 *는 찍히는 횟수가 반복할 때마다 1회 증가하면서 찍힌다. 다음과 같다.
@*@**@***@****@*****@******@*******@********@*********@**********@***********@************@*************@**************@***************@****************@*****************@******************@*******************@********************@*********************@**********************@***********************@************************@*************************@**************************@**********
위 음양 코드가 어떻게 동작하는지 하나씩 분석해보자.
먼저 을 보자. 위에서 나왔던 전형적인 후속문 이디엄이 나온다. call/cc는 호출된 지점에서의 후속문 함수를 캡처해서 바로 리턴한다. 리턴된 후속문 함수를 인자로 해서 람다 함수 (lambda (k) (display #\@) k) 호출된다. 이 람다 함수는 문자 @를 찍고는 인수 k에 저장된 후속문 함수를 다시 리턴한다. 후속문 함수는 이제 yin 지역변수에 저장된다. 요약하면 call/cc에서 후속문 함수를 캡처한 후, 문자 @를 찍고, 캡처한 후속문 함수를 지역변수 yin에 저장하는 것이다.
도 찍히는 문자 *만 다를 뿐 비슷한 코드여서 코드가 하는 일을 다음과 같이 요약할 수 있다. call/cc에서 후속문 함수를 캡처한 후, 문자 *를 찍고, 캡처한 후속문 함수를 지역변수 yang에 저장한다.
에서는 yin은 첫 번째 후속문 함수이고 yang은 두 번째 후속문 함수이므로, 첫 번째 후속문 함수가 두 번째 후속문 함수를 인자로 해서 호출되는 것이다.
이제부터 편의상 yin에 저장된 첫 번째 후속문 함수를 음 후속문 함수라고 부르고, yang에 저장된 두 번째 후속문 함수를 양 후속문 함수라고 부르겠다. 그러면 음 후속문 함수는 어떤 모양인지 보자.
아래에 첫 번째 call/cc에 의해서 캡처될 음 후속문을 보라색 바탕의 이탤릭체으로 표기하였다.
(let* ((yin ((lambda (k) (display #\@) k) (call/cc (lambda (k) k))))
(yang ((lambda (k) (display #\*) k) (call/cc (lambda (k) k)))))
(yin yang))v 표기법에 따라 call/cc 자리를 v로 표기하면 음 후속문 함수는 다음과 같다.
(lambda (v)
(let* ((yin ((lambda (k) (display #\@) k) v)) (1)
(yang ((lambda (k) (display #\*) k) (call/cc (lambda (k) k))))) (2)
(yin yang))) (3)| 1 | v 표기법 적용. 인수 v는 yin에 저장된다. 문자 @를 찍는다. |
| 2 | call/cc가 호출되면서 새로운 양 후속문 함수가 캡처되어 yang에 저장된다. 문자 *를 찍는다. |
| 3 | yin에 저장된 함수가 yang에 저장된 후속문 함수를 인자로 해서 호출된다. |
위의 음 후속문 함수의 특이한 점은 후속문 함수 안에서 또 call/cc를 호출하면서 새로운 후속문 함수를 캡처하고 있다는 점이다. 즉 음 후속문 함수가 호출될 때마다, 새로운 양 후속문 함수가 생성된다.
다음으로 양 후속문 함수가 어떤 모양일지 보자.
아래에 두 번째 call/cc에 의해서 캡처될 양 후속문을 보라색 바탕의 이탤릭체으로 표기하였다. 연두색 바탕의 이탤릭체으로 표기한 코드는 두 번째 call/cc가 호출되기 이전에 이미 실행된 선행문이다. 이 선행문은 캡처되지 않는다.
(let* ((yin ((lambda (k) (display #\@) k) (call/cc (lambda (k) k))))
(yang ((lambda (k) (display #\*) k) (call/cc (lambda (k) k)))))
(yin yang))v 표기법에 따라 call/cc 자리를 v로 표기하면 양 후속문 함수는 다음과 같다.
(let ((yin #<yin-continuation>)) (1)
(lambda (v)
(let ((yang ((lambda (k) (display #\*) k) v))) (2)
(yin yang)))) (3)| 1 | 이미 실행된 선행문을 let 문으로 표현했다. |
| 2 | v 표기법 적용. 인수 v는 yang에 저장된다. *를 찍는다. |
| 3 | yin에 저장된 함수를 yang에 저장된 후속문을 인자로 해서 호출한다 |
에서 yin은 자유 변수[11]가 아니다. 양 후속문 함수가 캡처될 때, yin은 이미 음 후속문 함수를 저장하고 있는 상태이기 때문이다. 따라서 양 후속문 함수는 클로저(closure)인 셈이다. 클로저(closure)란, 함수인데 그것이 실행되는데 필요한 별도의 정보를 따로 지닌 함수를 말한다. 이 별도의 정보를 클로저의 환경(environment) 혹은 컨텍스트(context)라고 한다. 양 후속문 함수는 yin이라는 정보를 담은 컨텍스트를 갖는다. 그리고 그 컨텍스트에는 yin이 음 후속문 함수로 설정되어 있다. 위 코드에서는 에서처럼 이 컨텍스트를 let문으로 표현하였다.
음양 예제를 분석하기 위해 위 코드를 좀 더 간략하게 표기할 필요가 있다. 지역변수 yin과 yang은 간단히 각각 음과 양으로 바꾸어 표기한다. 음 후속문 함수와 양 후속문 함수는 간단히 각각 A와 B로 표기한다. 뒤에서 보겠지만 음 후속문 함수 A에서 계속 호출되면서 새로운 양 후속문 함수가 계속 캡처되는데, 이렇게 새로 캡처된 양 후속문 함수들은 B1, B2, B3 라고 표기한다. 또한 방금 위에서 언급한 컨텍스트는 []로 표기한다. 따라서 사실 양 함수는 컨텍스트가 있는 클로저이므로 B[…]로 표기한다. 그리고 @와 * 문자가 찍히는 것을 첫 번째 칼럼에 표시하겠다.
이에 따라서 음양 예제 17 코드는 다음과 같이 간략하게 표기된다.
@ 음 <- new A (1)
* 양 <- new B[음=A] (2)
(음 양) => (A B[음=A]) (3)| 1 | 음 후속문 함수 A가 캡처되어 음에 저장한다. 문자 @이 찍힌다. |
| 2 | 양 후속문 함수 B가 캡처된다. 이때 음=A라는 컨텍스트 정보가 붙는다. 양에 B[음=A]가 저장된다. 문자 *이 찍힌다. |
| 3 | 음은 A이고, 양은 B[음=A] 이므로, 호출 (음 양)은 (A B[음=A])가 된다. |
위 코드는 예제 17과 정확하게 같은 의미의 코드이다. 비록 실제 실행되지는 않는 코드이지만 최소한 우리의 분석 목적으로 사용하기에는 좋다. 왜냐하면 이 코드는 예제 17과는 달리 양 후속문 함수의 컨텍스트를 나타내고 있기 때문이다. 위에서 언급했다시피 양 후속문 함수 B는 클로저라서 실행시에 컨텍스트가 실제 무엇인지 파악하는 것이 중요하다. 그래서 이 코드에서는 후속문 함수 B 바로 뒤에 []를 붙여서 컨텍스트를 표기하였다. []안에는 함수 B가 실행시에 필요한 정보를 담는다. 여기서는 이 정보를 음 지역변수가 음 후속문 함수 A라는 의미로 음=A라고 표기하였다.
이제 똑같은 방식으로 예제 18의 음 후속문 함수도 다음과 같이 바꿀 수 있다.
@ 음 <- v (1)
* 양 <- new B[음=v] (2)
(음 양) => (v B[음=v]) (3)| 1 | 음 후속문 A가 호출되면, 그 인자는 인수 v로 들어와서 음에 저장된다. v 인자 대입법이 적용된다. 문자 @가 찍힌다. |
| 2 | 새로운 양 후속문 함수 B가 캡처되어 양에 저장된다. 이때 에 의해 음=v이 B의 컨텍스트 정보가 된다. B의 컨텍스트 []에 음=v를 넣는다. 그러므로 양에 저장되는 것은 B[음=v]이다. 문자 *이 찍힌다. |
| 3 | 음은 v이고, 양은 B[음=v] 이므로, 호출 (음 양)은 (v B[음=v])가 된다. |
위 음 후속문 함수의 코드에서 새로 캡처되는 양 후속문 함수 B는 실제 실행될 때마다 그 전에 캡처된 양 후속문 함수와 구별하기 위해 B1, B2, B3, …로 표기될 것이다.
이제 똑같은 방식으로 예제 19의 양 후속문 함수도 다음과 같이 바꿀 수 있다.
[음=?] (2)
* 양 <- v (1)
(음 양) => (? v) (3)| 1 | 양 후속문 함수 B가 호출되면, 인자는 인수 v로 들어와서 양에 저장된다. v 인자 대입법이 적용된다. 문자 *이 찍힌다. |
| 2 | 음은 양 후속문 B 호출시의 컨텍스트에서 이미 정해진 값이다. 현재 여기서는 컨텍스트에 무엇이 저장되어 있는지 모르므로 ?로 표기한다. |
| 3 | 음은 ?이고, 양은 v이므로, 호출 (음 양)은 (? v)가 된다. |
자 이제 모든 준비가 끝났다. 음양을 구동시켜 보자.
@ 음 <- B[음=A] (1)
* 양 <- new B1[음=B[음=A]] (2)
(음 양) => (B[음=A] B1[음=B[음=A]]) (3)| 1 | 예제 21의 인수 v가 인자 B[음 A]로 대체된다. v 인자 대입법의 적용이다. 문자 @가 찍힌다. |
| 2 | 새로운 양 후속문 B1이 캡처된다. 이때 음이 새로 캡처된 후속문 B1의 컨텍스트 정보이다. 그래서 B1의 컨텍스트 []에 음=B[음=A]를 넣는다. 양에는 B1[음=B[음=A]]가 저장된다. 문자 *가 찍힌다. |
| 3 | 음은 B[음=A]이고, 양은 B1[음=B[음=A]] 이므로, 호출 (음 양)은 (B[음=A] B1[음=B[음=A]])가 된다. |
이제 이 코드는 B1을 인자로 해서 B를 호출한다. 양 후속문 함수 B(예제 22)가 실행된다. 아래와 같다.
[음=A] (2)
* 양 <- B1[음=B[음=A]] (1)
(음 양) => (A B1[음=B[음=A]]) (3)| 1 | 인수 v가 인자 B1[음=B[음=A]]로 대체된다. v 인자 대입법의 적용이다. 문자 *가 찍힌다. |
| 2 | 호출된 후속문 함수인 B의 컨텍스트 정보이다. 이것은 B가 만들어질 때, 음이 A로 설정되었다는 사실을 나타낸다. |
| 3 | 음은 A이고, 양은 B1[음=B[음=A]] 이므로, 호출 (음 양)은 (A B1[음=B[음=A]])가 된다. |
이 코드는 예제 20과 똑같이 후속문 함수 A를 다시 호출한다. 다만 인자가 그 전보다 더 복잡해졌다. 처음에는 인자가 B[음=A]였는데, 이제는 B1[음=B[음=A]]이다.
이제 음 후속문 함수 A(예제 21)가 다시 아래와 같이 실행된다.
@ 음 <- B1[음=B[음=A]] (1)
* 양 <- new B2[음=B1[음=B[음=A]]] (2)
(음 양) => (B1[음=B[음=A]] B2[음=B1[음=B[음=A]]]) (3)| 1 | 인수 v가 인자 B1[음=B[음=A]]로 대체된다. v 인자 대입법의 적용. 문자 @가 찍힌다. |
| 2 | 새로운 양 후속문 B2가 캡처된다. 이때 음이 새로 캡처된 후속문 B2의 컨텍스트 정보가 된다. 그래서 B2의 컨텍스트 []에 음=B1[음=B[음=A]]]를 넣는다. 양에 B2[음=B1[음=B[음=A]]]가 저장된다. 문자 *가 찍힌다. |
| 3 | 음은 B1[음=B[음=A]]이고, 양은 B2[음=B1[음=B[음=A]]] 이므로, 호출 (음 양)은 (B1[음=B[음=A]] B2[음=B1[음=B[음=A]]])가 된다. |
자 이제 위 코드에서는 B1이 호출된다. 그러면 양 후속문 함수(예제 22)가 실행될 것이다. 이것이 실행되면 예제 24에서처럼 B1의 컨텍스트가 [음=B[음=A]]이므로 다음에는 B가 실행된다. 그리고 B의 컨텍스트가 [음=A]이므로 다음에는 A가 실행된다. 다시 또 A가 실행되는 것이다. 대신 인자는 더 복잡해질 것이다. 그리고 A가 실행되면서 새로운 후속문 B3가 만들어질 것이다. B3의 컨텍스트는 [음=B2[…]]일 것이다. 또 반복이다. 결국, 이 모든 과정에서 호출되는 후속문들의 연쇄는 아래와 같이 되는 것이다.
A -> B -> A -> B1 -> B -> A -> B2 -> B1 -> B -> A -> B3 -> B2 -> B1 -> B ...
이제 A를 @로, B들은 *로 바꾸면 된다.
@ -> * -> @ -> * -> * -> @ -> * -> * -> * -> @ -> * -> * -> * -> * ...
전체적인 전개 과정은 다음과 같다.
@ 음 <- new A
* 양 <- new B1[음 A]
(음 양) => (A B1[음 A])
-------------------------------------------------------------------
@ 음 <- B1[음 A]
* 양 <- new B2[음 B1[음 A]]
(음 양) => (B1[음 A] B2[음 B1[음 A]])
[음 A]
* 양 <- B2[음 B1[음 A]]
(음 양) => (A B2[음 B1[음 A]])
-------------------------------------------------------------------
@ 음 <- B2[음 B1[음 A]]
* 양 <- new B3[음 B2[음 B1[음 A]]]
(음 양) => (B2[음 B1[음 A]] B3[음 B2[음 B1[음 A]]])
[음 B1[음 A]]
* 양 <- B3[음 B2[음 B1[음 A]]]
(음 양) => (B1[음 A] B3[음 B2[음 B1[음 A]]])
[음 A]
* 양 <- B3[음 B2[음 B1[음 A]]]
(음 양) => (A B3[음 B2[음 B1[음 A]]])
-------------------------------------------------------------------
@ 음 <- B3[음 B2[음 B1[음 A]]]
* 양 <- new B4[음 B3[음 B2[음 B1[음 A]]]]
(음 양) => (B3[음 B2[음 B1[음 A]]] B4[음 B3[음 B2[음 B1[음 A]]]])
[음 B2[음 B1[음 A]]]
* 양 <- B4[음 B3[음 B2[음 B1[음 A]]]]
(음 양) => (B2[음 B1[음 A]] B4[음 B3[음 B2[음 B1[음 A]]]])
[음 B1[음 A]]
* 양 <- B4[음 B3[음 B2[음 B1[음 A]]]]
(음 양) => (B1[음 A] B4[음 B3[음 B2[음 B1[음 A]]]])
[음 A]]
* 양 <- B4[음 B3[음 B2[음 B1[음 A]]]]
(음 양) => (A B4[음 B3[음 B2[음 B1[음 A]]]])
yin-yang 예제는 후속문 프로그래밍이 어떻게 힘을 발휘하게 되는지를 보여준다. 하지만 이 예제는 그리 실용적이지 않다. 이젠 후속문 프로그래밍의 막강한 힘이 어떻게 유용하게 사용되는지 볼 차례가 되었다. 후속문 프로그래밍의 힘은 기존에는 없었던 제어 흐름 구조를 만들어 낼 수 있다는 점이다. 바로 이런 점을 보여주는 예로 비결정적 선택이라는 예제를 볼 것이다.
2.11. 비결정적 선택(Nondeterministic Choice)
컴퓨터 공학에서 비결정성(Nondeterminism)[12] 이란 프로그램의 제어가 어디로 가게 될 지를 사전에 알 수 없고, 런타임에 임의로 그 흐름이 결정되는 것을 말한다. 즉 랜덤값이 아니라 랜덤제어흐름이다. 비결정성의 대표적인 것이 스레드이다. 선점형 스레딩 모델에서 한 스레드에서 다른 스레드로 제어가 넘어가는 것은 비결정적이다. 스레드의 이런 비결정성을 프로그래머가 처리하도록 한 것은 최악의 선택이었다. 스레드는 비결정성이 잘못 도입된 대표적인 예이다.
하지만 때로는 비결정성의 도입이 문제 해결에 더 좋은 방법을 제공하기도 한다. 이런 경우에 비결정적 알고리즘(Nondeterministic algorithm)이라는 방식을 사용한다. 보통 알고리즘은 주어진 입력에서 출력까지에 이르는 하나의 로직의 흐름이라고 할 수 있다. 즉 입력이 주어지면 하나의 로직 경로를 거쳐서 하나의 출력이 나온다는 점에서 결정론적이다. 결정론적 알고리즘에서 중요한 것은 그 하나의 로직 경로를 잘 설계하는 것이다. 반면 비결정적 알고리즘은 하나의 로직 경로를 설계하는데 관심을 두지 않는다. 대신 하나의 입력에서 나올 수 있는 가능한 모든 출력에 이르는 경로들을 탐색하면서, 해당 출력들 중에서 정답을 선택한다. 비결정적 알고리즘은 결국 모든 해를 준비해놓고 각 해가 맞는지 틀리는지만 정해주는 방식이다. 그래서 비결정적 알고리즘에서 중요한 것은 하나의 해를 찾는 로직이 아니라 모든 가능한 해를 탐색하는 로직이 중요하다. 그 탐색에서 우리는 어느 것이 정답인지를 선택하면 된다. 비유를 하자면 결정적 알고리즘은 도끼 찾으러 호수 속으로 직접 뛰어 들어가는 것이다. 이때 중요한 것은 도끼까지의 경로이다. 반면 비결정적 알고리즘은 호수 속 모든 도끼를 찾을 수 있는 산신령이 나타나 하나씩 '이 도끼가 네 도끼냐?'하고 물으면 '제 도끼가 아닙니다’라거나 '제 도끼가 맞습니다’라고 말하면서 금도끼[13]를 선택하는 것이다. 여기서 중요한 것은 모든 도끼를 가져올 수 있는 산신령이다. 이 산신령만 있다면 선택하는 것은 매우 쉬우니 도끼 찾는 일은 식은 죽 먹기가 된다. 그럼, 이 산신령을 어떻게 만들어 낼 수 있을까? 관건은 탐색을 자동화하는 것이다.[14]
비결정적 알고리즘은 2가지 로직으로 구성된다. 하나는 전체 해를 찾는 자동화된 탐색 로직이고, 다른 하나는 선택하는 로직이다. 전자가 산신령이라면, 후자는 나무꾼이다. 나무꾼이 하는 일은 금도끼인지 아닌지만 테스트하는 아주 쉬운 일이다(튼튼한 이빨과 질산만 있으면 된다). 산신령이 하는 일은 호수 속의 모든 도끼를 빠짐없이 하나씩 찾아서 나무꾼에게 보여주는 것이다.
다음은 주어진 자연수 집합에서 피타고라스 수를 비결정적 방식으로 찾는 코드이다. 예상했겠지만 자연수를 탐색하는 로직을 만드는데 역시 후속문을 사용한다.[15]
(define (cc) (1)
(call/cc (lambda (k) k)))
(define fail-stack '()) (2)
(define (push-k k)
(set! fail-stack (cons k fail-stack)))
(define (pop-k)
(let ((k (car fail-stack)))
(set! fail-stack (cdr fail-stack))
k))
(define (fail) (3)
(if (empty? fail-stack)
(error "backtracking stack exhausted!")
(begin
(let ((backtrack-point (pop-k)))
(backtrack-point backtrack-point)))))
(define (amb choices) (4)
(let ((k (cc)))
(if (empty? choices)
(fail)
(let ((choice (car choices)))
(set! choices (cdr choices))
(push-k k)
choice))))
(define (assert condition) (5)
(if (not condition)
(fail)
#t))
(let ((a (amb (list 1 2 3 4 5 6 7))) (6)
(b (amb (list 1 2 3 4 5 6 7))) (7)
(c (amb (list 1 2 3 4 5 6 7)))) (8)
(assert (= (* c c) (+ (* a a) (* b b)))) (9)
(println (list a b c)))
;>> (3 4 5)| 1 | cc 함수는 현재 시점에서의 후속문 함수를 반환한다. 앞에서 설명했던 후속문 이디엄을 함수화한 것이다. |
| 2 | fail-stack은 후속문 함수들을 담는 스택이다. |
| 3 | fail 함수는 fail-stack에서 후속문 함수 하나를 꺼내서 실행한다. 없으면 예외를 던진다. 호출시에 이 후속문 함수의 인자는 자기 자신이다. |
| 4 | amb 함수는 후속문 함수를 생성해서 fail-stack에 넣는다. 그리고 인수 choices 리스트에서 요소 하나를 꺼내 리턴한다. 리스트가 소진되면 fail 함수를 호출한다. |
| 5 | assert 함수는 인수로 받은 condition이 거짓이면 fail 함수를 호출한다. 참이면 #t를 리턴한다. |
| 6 | (list 1 2 3 4 5 6 7)을 비결정적 선택으로 만든다. a는 비결정적 요소가 된다. |
| 7 | (list 1 2 3 4 5 6 7)을 비결정적 선택으로 만든다. b는 비결정적 요소가 된다. |
| 8 | (list 1 2 3 4 5 6 7)을 비결정적 선택으로 만든다. c는 비결정적 요소가 된다. |
| 9 | 피타고라스 수가 되는 a, b, c를 선택한다. |
위 코드에서 재밌는 부분은 이다. 먼저 이 코드들을 해석해보자. 의미론적으로.
우선 핵심은 amb 함수[16]이다. 이 함수는 리스트를 받아서 호출시마다 리스트의 요소를 하나씩 리턴한다. 함수의 내부 구현은 그렇게 되어 있지만, 의미론적 관점에서는 다르게 해석해야 한다. 이 함수가 리턴한 것은 그냥 리스트의 요소가 아니라, 인수로 받은 리스트의 요소 중 어느 것이다. 그런데 그 어느 것이 결정된 것은 아니다. 리스트의 요소 중 어느 것이 나올지는 모른다. 혼재되어 있다. 그래서 'ambiguous’이다. 위 코드의 에서 a, b, c 각각은 1~7의 숫자 중에서 임의의 하나를 나타낸다.
는 a, b, c중 피타고라스 수의 조건에 맞는 실제의 a, b, c 값을 결정한다. a, b, c는 원래 1~7의 숫자 중에서 어떤 값으로도 결정되지 않은 상태인데, assert 함수의 조건을 만나는 순간 그 조건에 맞는 값들로 a, b, c가 결정되는 것이다. 이것은 마치 양자역학에서 한 입자가 측정하기 전까지는 어떤 값으로도 결정되지 않은 양자 상태에 있다가 측정을 하는 순간 하나의 값으로 상태가 결정되는 것과 같다.
~ 까지의 코드를 보면, 그냥 문제를 기술한 것으로 보인다. 즉 a, b, c는 각각 1~7까지의 숫자이다. c가 빗변이라고 할 때 피타고라스 수가 되는 a, b, c를 구하라. 환상적이지 않나? 어떻게 이게 가능한가? 산신령이 나셨기 때문….이 아니고.
여기까지가 의미론적 해석이다. 이것이 작동하려면 결국 a, b, c의 값들의 조합이 생성되어 assert 함수가 실행되는데, 실패하면 다시 새로운 a, b, c의 값들의 조합을 가져와서 assert 함수가 성공할 때까지 실행되는 것이다.
사실 위의 이 탐색 로직이고 가 선택 로직이다.
이 로직은 다음과 같이 동작한다.
-
에서 리스트가 비었으면 초기화한다(리스트 a라고 하자). 있으면 요소 하나를 꺼내
a에 넣는다. -
에서 리스트가 비었으면 초기화한다(리스트 b라고 하자). 있으면 요소 하나를 꺼내
b에 넣는다. -
에서 리스트가 비었으면 초기화한다(리스트 c라고 하자). 있으면 요소 하나를 꺼내
c에 넣는다. -
에서
a,b,c에 대해assert함수를 수행한다.-
실패이면 3으로 간다.
-
성공이면
println하고 종료.
-
-
3~4가 반복된다. 리스트 c가 소진될 때까지.
-
리스트 c가 소진되면 2로 간다.
-
2~6가 반복된다. 리스트 b가 소진될 때까지.
-
리스트 b가 소진되면 1로 간다.
-
1~7가 반복된다. 리스트 a가 소진될 때까지.
위의 과정으로 탐색이 수행되면서 a, b, c는 (1 1 1), (1 1 2), (1 1 3)…(7 7 6), (7 7 7)까지 모든 가능한 해를 지니게 된다. 그중에서 assert 함수에 주어진 조건에 맞는 것을 선택하게 되는 것이다.
위의 과정을 보면 제어가 assert 함수 실패시에는 로, c 리스트가 소진되면 로, b 리스트가 소진되면 으로 이동하는 것을 볼 수 있다. 이렇게 제어를 이동시키는 역할을 하는 것이 fail 함수이다.
fail 함수는 제어를 관리하기 위해 fail-stack을 이용한다. fail-stack은 amb 함수에서 만들어진 후속문 함수를 담고 있다. fail 함수는 fail-stack에서 마지막으로 들어간 후속문 함수를 꺼내서 실행한다. 이 말은 곧 그 후속문 함수가 생성된 곳으로 제어를 옮긴다는 의미다. 그래서 fail-stack에서 꺼낸 후속문 함수를 받는 지역 변수 이름이 backtrack-point인 것이다. 그리고 인자도 함께 넘기는데 backtrack-point 자기 자신이다. 이렇게 제어와 인자가 넘겨지는 곳은 amb 함수 내의 cc 함수가 호출된 자리이다.
amb 함수가 하는 일은 지역변수 k에 바인딩된 후속문 함수를 fail-stack에 넣고, choices에서 꺼낸 수를 리턴하는 것이다. amb 함수는 사실 2가지 경로로 실행된다. 하나는 amb 함수를 호출하면서 실행되는 경로이고, 다른 하나는 후속문 함수의 호출로 제어가 amb 함수로 넘어오면서 실행되는 경로이다. 이 2가지 경로에 따라 인수 choices도 달라지고, 지역변수 k에 후속문 함수가 바인딩되는 방식도 달라진다. amb 함수를 호출하는 경우에는 인수 choices에는 새로운 인자 (list 1 2 3 4 5 6 7)이 들어와서 초기화되고, 지역 변수 k에는 cc 함수에 의해 새로 캡처된 후속문 함수가 바인딩된다. 하지만 이 후속문 함수가 fail 함수에 의해 호출되면서 제어가 다시 amb 함수로 넘어오는 경우에는 choices는 기존값을 계속 사용하게 되고, 지역 변수 k에도 기존 후속문 함수가 바인딩된다. 그래서 제어가 fail 함수에서 amb 함수로 넘어올 때마다 choices는 하나씩 자신의 원소를 꺼내게 되어 계속 줄어들게 되고, fail-stack은 pop 되었던 기존 후속문 함수가 다시 push 되면서 이전과 똑같아진다. 이로써 amb 함수 이후의 코드(예를 들어 assert 함수)는 다른 모든 것은 똑같은 채 단지 choices에서 꺼내온 다음 요소로 실행되게 된다. 그러다가 choices가 소진되면 amb 함수는 fail 함수를 호출한다. 하지만 fail-stack에는 다른 후속문 함수가 들어있으므로 fail 함수는 다른 곳으로 제어를 옮긴다.
이제 전체 동작이 어떻게 이루어지는지 하나씩 살펴보자.
먼저 을 보자. amb함수가 실행되면서 cc 함수가 캡처한 후속문 함수를 fail-stack에 넣는다. 이 후속문 함수를 a 후속문 함수라고 하자. 그리고 리스트에서 요소 하나를 꺼내서 리턴한다. 그래서 a는 1이 된다. 이제 에서도 마찬가지로 amb 함수가 실행되면서 b 후속문 함수가 fail-stack에 들어가고, 리스트에서 요소 하나를 빼와서 리턴한다. 그래서 b는 1이 된다. 에서도 마찬가지로 c 후속문 함수가 스택에 들어가고, c는 1이 된다.
그 다음으로 의 assert 함수가 처음 실행되는데, 이때 a, b, c는 각각 1, 1, 1이다. assert 함수는 조건이 참이 아니라서 fail 함수를 실행하게 된다. 위에서 언급했다시피 fail 함수는 제어를 관리한다. fail 함수는 fail-stack에 가장 마지막에 들어간 c 후속문 함수를 꺼내서 실행한다. 그래서 제어는 로 이동한다. 의 amb 함수가 수행되면서 인자로 전달된 c 후속문 함수는 다시 fail-stack에 들어가고, c 리스트에서 2를 꺼내서 c에 바인딩한다.
다시 의 assert 함수가 실행되는데, 이젠 a, b, c가 각각 1, 1, 2이다. 이번에도 assert 함수가 실패하면서 다시 fail 함수가 실행된다. fail 함수는 바로 위의 과정을 또 반복하면서 c는 이제 3이 된다. 이런 과정은 c의 리스트가 소진될 때까지 반복 진행된다.
c의 리스트가 소진되면 amb는 fail 함수를 호출한다. fail 함수는 fail-stack에서 마지막 요소를 꺼내 실행하는데, 그게 이번에는 b 후속문 함수이다. 제어는 이번에는 로 이동하는 것이다. 의 amb 함수가 수행되면서 b 후속문 함수는 다시 fail-stack에 들어가고, b 리스트에서 2를 꺼내 b에 바인딩한다. 다음으로 의 amb 함수가 실행되면서 c 후속문 함수가 다시 생성되어 fail-stack에 들어가고, c는 1이 된다.
다시 의 assert 함수가 실행되는데, 이젠 a, b, c가 각각 1, 2, 1이다. 역시 assert 함수가 실패하면서 c의 리스트가 소진된 때까지의 과정이 반복된다. c의 리스트가 소진되어서 제어는 다시 로 이동하고 b는 이제 3이 되어 바로 위의 과정을 다시 반복하게 된다. b가 소진될 때까지.
이런 과정은 b 리스트가 소진되어 제어가 으로 이동하는 과정까지 반복된다. 이제 a가 2가 된다. assert 함수는 2, 1, 1에 대해 테스트한다. 그러다가assert의 조건이 참이 되는 때에 중단하게 되는데 a, b, c 가 각각 3, 4, 5가 될 때이다. assert가 참이 되어 제어는 바로 뒤의 println 문으로 이동해서 (3 4 5)를 찍고 종료된다.
지금까지 call/cc를 이용하여 amb 함수를 만들어서 비결정적 선택 방식으로 피타고라스 수를 찾는 예제를 살펴보았다. 위 예제에서 (3 4 5) 이외의 다른 해를 찾고 싶다면 fail 함수를 호출하면 된다. 맨 마지막 라인 (println (list a b c))) 식 아래에 (fail) 코드를 넣고, 다시 그 아래 (println (list a b c)))를 넣고 실행해보자. 그러면 (3 4 5)와 (4 3 5)가 찍히는 것을 확인할 수 있다.
그런데 아마도 독자들은 for 문을 이용하면 같은 결과를 낼 수 있다는 것을 알 수 있을 것이다. 삼중 for 문을 하면 정확히 같은 결과가 나온다. 그런데 왜 굳이 amb를 만들었을까? 사실 amb는 Backtracking이라는 기법을 지원하기 위한 제어구조이다. Planner라는 프로그래밍 언어는 amb를 제어구조로서 언어 차원에서 지원한다. Backtracking 기능을 이용하면 논리 프로그래밍이 가능해진다. 실제로 논리 프로그래밍 언어인 Prolog가 이에 기반해 있다. amb에 대한 더 많은 정보를 얻고 싶다면 비결정성(Nondeterminism)을 다루는 SICP 4.3 절과 On Lisp의 22장을 보기 바란다.
2.12. 코루틴
코루틴은 서브루틴과 비교된다. 보통 코루틴을 일반화된 서브루틴이라고 한다. 반대로 서브루틴은 코루틴의 특수한 버전이라고 할 수 있다. 코루틴이 서브루틴보다 더 포괄적인 개념인 것이다. 어떤 점에서 그럴까? 서브루틴은 진입점이 서브루틴의 처음으로 고정되어 있지만, 코루틴은 진입점이 고정되어 있지 않아, 코루틴의 어느 곳이나 진입점이 될 수 있다는 점에서 그렇다. 진입점이란 호출자로부터 피호출자가 제어를 넘겨받는 곳을 말한다. 호출자가 서브루틴을 호출하면 제어는 서브루틴의 처음으로 넘어간다. 서브루틴의 진입점은 서브루틴의 처음이며, 그리고 바로 그것 하나뿐이다. 코루틴도 호출자가 호출하면 코루틴의 처음으로 제어가 이동한다. 하지만 코루틴은 코루틴의 처음이 아닌 코루틴의 어느 곳에서도 제어를 넘겨받을 수 있는 도구가 따로 있다. 이 도구를 사용하면 코루틴은 진입점이 여러 개가 될 수 있다. 바로 이런 점에서 코루틴이 서브루틴보다 더 포괄적이라고 하는 것이다. 반대로 서브루틴은 진입점이 함수의 처음에만 있는 특수한 코루틴이라고 할 수 있다.
그렇다면 코루틴의 진입점을 여러 개 만들 수 있게 하는 그 도구가 무엇일까? 그것은 yield 문이다. yield 문은 return 문과 비교되는데, 둘 다 제어를 호출자에게 넘긴다는 점에서 같다. 하지만 return 문과 달리 yield 문은 제어를 넘기는 그 자리를 진입점으로 만든다. 그래서 나중에 그 진입점으로 다시 제어가 돌아올 수 있다. 어떤 코루틴 A가 yield를 하면 제어가 다른 코루틴 B로 넘어가는데, 코루틴 B가 제어를 받아 처리하다가 yield를 하면, 이번에는 제어가 코루틴 A가 yield했던 자리로 넘어가는 것이다. 이런 식으로 코루틴 A와 B가 서로의 실행의 중간 지점들에서 제어를 주거니 받거니 할 수 있는 것이다.
코루틴의 이런 특성 때문에 코루틴은 협력적 스레딩(Cooperative threading)에 사용될 수 있다. 코루틴끼리 서로 제어를 주거니 받거니 하면서 필요한 작업을 협력적으로 수행할 수 있기 때문이다. 서로 협력적으로 일하니 리소스 경쟁이 없고, 경쟁이 없으니 뮤텍스나 세마포어 같은 동기화 장치를 쓸 필요도 없다. 그래서 동시성 프로그래밍이 매우 단순해진다.
yield에 대해 가만히 생각해보자. yield에 의해 제어를 넘겨받은 코루틴에게는 그 yield 이후의 코드는 후속문이 된다. 왜냐하면 제어를 넘겨받은 코루틴이 실행된 이후에 실행될 코드가 yield 이후의 코드이기 때문이다. 그래서 코루틴을 후속문으로 구현하는 것이 가능해진다. 즉 yield 뒤에 있는 코드를 캡처해서 후속문 함수로 만들고, 나중에 그 후속문 함수를 호출하면서 제어를 넘길 수 있기 때문이다.
다음은 코루틴을 후속문으로 구현한 예제이다.[17]
(define thread-queue '()) (1)
(define (enqueue thread)
(set! thread-queue (append thread-queue (list thread))))
(define (dequeue)
(let ((thread (car thread-queue)))
(set! thread-queue (cdr thread-queue))
thread))
(define halt #f) (2)
(define (cc) (3)
(call/cc (lambda (k) k)))
(define (spawn thunk) (4)
(let ((k (cc)))
(if (procedure? k)
(enqueue k)
(begin (thunk)
(quit)))))
(define (yield) (5)
(let ((k (cc)))
(if (and (procedure? k) (not (empty? thread-queue)))
(let ((next-thread (dequeue)))
(enqueue k)
(next-thread 'resume))
(void))))
(define (quit) (6)
(if (empty? thread-queue)
(halt)
(let ((next-thread (dequeue)))
(next-thread 'resume))))
(define (start-threads) (7)
(let ((k (cc)))
(if k
(begin
(set! halt (lambda () (k #f)))
(if (empty? thread-queue)
(void)
(begin
(let ((next-thread (dequeue)))
(next-thread 'resume)))))
(void))))
;; 제어를 서로 주거니 받거니 하면서 협력하는 스레드 예제
(define counter 10)
(define (make-thread-thunk name)
(letrec ((loop (lambda ()
(if (< counter 0)
(quit)
(begin
(printf "in thread ~a; counter = ~a\n" name counter)
(set! counter (- counter 1))
(yield)
(loop))))))
loop))
(spawn (make-thread-thunk 'a)) (9)
(spawn (make-thread-thunk 'b)) (10)
(spawn (make-thread-thunk 'c)) (11)
(start-threads) (12)
;=> in thread a; counter = 10
;=> in thread b; counter = 9
;=> in thread c; counter = 8
;=> in thread a; counter = 7
;=> in thread b; counter = 6
;=> in thread c; counter = 5
;=> in thread a; counter = 4
;=> in thread b; counter = 3
;=> in thread c; counter = 2
;=> in thread a; counter = 1
;=> in thread b; counter = 0| 1 | 스레드를 넣고 빼는 큐를 정의한다. |
| 2 | halt는 모든 실행을 중단하는 함수로 설정될 것이다. 현재는 #f이지만 나중에 할당된다. |
| 3 | cc 함수는 후속문 이디엄을 함수화한 것이다. 위에서 설명되었던 바이다. |
| 4 | spawn 함수를 정의한다. 지역변수 k가 함수이면 그것을 스레드 큐에 넣고, 아니면 thunk 인수로 주어진 함수를 실행한다. |
| 5 | yield 함수는 yield의 구현이다. 스레드 큐에서 스레드를 하나 꺼내서 제어를 넘기고, 현재 시점의 후속문을 캡처해서 스레드 큐에 넣는다. |
| 6 | quit 함수를 정의한다. 스레드 큐가 비었으면 halt를 해서 모든 실행을 중단한다. 아니면 큐에서 스레드 하나를 꺼내서 실행한다. |
| 7 | start-threads 함수는 스레드들을 시작시킨다. 스레드 큐에서 하나씩 꺼내서 실행한다. |
| 8 | make-threads-thunk 함수는 스레드를 만드는 함수이다. |
| 9 | 스레드 a를 만들어서 스레드 큐에 넣는다. |
| 10 | 스레드 b를 만들어서 스레드 큐에 넣는다. |
| 11 | 스레드 c를 만들어서 스레드 큐에 넣는다. |
| 12 | 전체 스레드를 구동한다. |
start-threads 함수부터 보자. cc 함수로 후속문 함수를 캡처해서 지역변수 k에 바인딩한다. if 문에서 k가 참이 되므로 begin 문이 실행된다. halt 변수에 후속문 함수 k를 인자 #f로 호출하는 람다 함수로 설정한다. 그러고나서 스레드 큐를 검사하는데, 비었으면 void 함수를 호출한다. void 함수는 #<void>를 리턴하는데 마치 아무것도 리턴하지 않는 효과를 갖는다. 그래서 start-thread 함수는 리턴값없이 리턴한다. 스레드 큐가 비어있지 않으면 스레드 하나를 꺼내서 'resume을 인자로 해서 실행한다. 현재는 spawn 함수에 의해서 스레드 큐에 스레드가 들어가 있기 때문에 start-thread는 바로 끝나지 않는다. 만약 k를 검사하는 if 문에서 k가 거짓이면 역시 void 함수를 호출해서 start-thread 함수는 리턴없이 끝나게 된다. 방금 설정했던 halt 함수가 start-thread 함수에서 캡처했던 후속문 함수 k를 #f를 인자로 해서 호출하고 있다. 따라서 halt 함수 호출하면 start-tread 함수가 끝나게 된다.
다음으로 spawn 함수를 보자. cc 함수로 후속문을 캡처해서 지역변수 k에 바인딩한다. 지역변수 k를 procedure? 함수로 함수 여부를 검사한다. 후속문 함수는 프로시저이므로 스레드 큐에 들어가게 된다. k가 procedure? 검사에서 실패하는 경우는 spawn 함수가 방금 캡처한 후속문 함수가 아닌 다른 인자로 호출될 때이다. 그때는 thunk 함수를 실행한다. thunk 함수는 make-thread-thunk 함수에서 리턴된 loop이다.
make-thread-thunk 함수는 람다 함수를 만들어 지역변수 loop에 할당하는데, 이 람다 함수 끝에서 loop을 다시 호출하고 있기 때문에 이 람다 함수는 재귀호출함수가 된다. make-thread-thunk 함수는 이 재귀호출함수 loop을 리턴한다. loop 함수가 실행되면 display 함수를 호출해서 프린트한다. 그러고나서 다시 loop을 호출해서 재귀하기 전에 yield 함수를 호출한다.
yield는 코루틴에서 제어를 넘길 때 쓰는 것이다. yield 함수는 현시점에서의 후속문을 캡처해서 지역변수 k에 넣는다. 지역변수 k가 후속문 함수이고, 스레드 큐가 비어있지 않으면 지역변수 k에 들어있는 후속문 함수를 큐에 넣고, 큐에서 스레드 하나를 꺼내서 실행한다. 만일 yield 함수에서 캡처된 후속문 함수가 호출되면 지역변수 k는 함수가 아니어서 yield 함수는 리턴한다.
자 이제 하나씩 실행 과정을 살펴보자. , 에서 spawn 함수에 의해 스레드가 만들어져서 스레드 큐에 차례대로 들어간다. 이 스레드 함수들이 호출되면 loop 함수가 실행될 것이다. 이제 의 start-threads 함수에 의해서 스레드 전체가 구동되기 시작한다. 스레드 큐에서 제일 먼저 스레드 'a가 먼저 꺼내져서 실행된다. loop 함수에서 yield가 호출된다. yield 호출에 의해 yield 이후 후속문 함수가 스레드 큐에 들어가고, 기존에 있던 스레드가 스레드 큐에서 꺼내져서 실행된다. 이것은 스레드 'b이다. 스레드 'b에서도 yield가 실행되고, 다음 스레드 'c가 실행된다. 스레드 'c도 yield를 호출하고, 스레드 큐에서 스레드를 꺼내는데, 이 스레드는 spawn 함수에 의해서 캡처된 것이 아니라 스레드 'a의 yield에 의해서 캡처된 후속문 함수이다. 그러면 결국 제어는 loop 함수의 yield으로 이동하는데, 거기서 다시 loop을 호출하므로 재귀가 된다. 그러면서 또 같은 위치에서 제어를 양보하게 된다. 이런 식으로 계속해서 후속문 함수가 생성되어 큐에 들어가고 큐에서 후속문 함수를 꺼내서 실행하면서 스레드들끼리 서로 제어를 넘겨받게 된다. 그러면서 count를 하나씩 감소시키는데, count가 0보다 작아지면 quit 함수를 호출한다. quit 함수는 스레드 큐에 남아있는 스레드들을 다 실행시키다가 스레드 큐가 비면 halt 함수를 호출해서 전체 실행을 끝낸다.
이 예제에서 보여준 코루틴은 매우 초보적인 수준이다. 실제 프로그래밍 언어 차원에서 제공되는 코루틴의 구현을 위해서는 더 복잡한 기능들이 추가되어야 한다. 코루틴을 어떻게 구현할 것이냐에 따라 여러가지로 분류되기도 한다. 이에 대해 좋은 한글 자료로는 한주영님의 블로그 글를 보면 좋을 듯 하다.
코루틴과 구분되는 것으로 파이버(Fiber)가 있다. 파이버는 코루틴에 전용의 스케줄러를 추가한 개념이다. 실제로 자바에서 파이버를 구현하는 프로젝트인 Loom Project에서는 ForkJoinPool을 스케줄러로 사용해서 파이버를 구현하고 있다.
또 코루틴과 비교될 수 있는 것이 최근에 소개되고 있는 CSP 프로그래밍의 고루틴(go routine)이다. Go 언어에서 많이 사용되고 있는데, 사실 후속문이라는 점에서는 코루틴과 같다. 다만 코루틴은 단일 스레드 상에서만 동시성이 보장되지만, 고루틴은 멀티 스레드 상에서도 동시성을 보장할 수 있도록 채널이라는 동시성 지원 장치를 이용한다는 점이 다르다. 단일 스레드에서만 동시성이 보장되는 것은 파이버도 마찬가지다.
3. 1부를 마치면서
지금까지 후속문의 개념에 대한 정의와 후속문이 call/cc에 의해서 어떻게 다루어지는지, 그리고 call/cc 함수로 다양한 후속문 프로그래밍에 대해 알아보았다. yin-yang 예제는 call/cc를 통한 후속문 프로그래밍이 어떤 힘을 가질 수 있는지를 보여주었다. 비결정적 선택 예제는 프로그래머가 얼마든지 언어에서는 제공하지 않는 제어구조를 만들 수 있다는 점을 보았다. 코루틴 예제는 컴파일러들이 제공하는 대표적인 제어 흐름 구조를 후속문으로 구현해 보았다. 후속문은 이 밖에도 제너레이터(Generator)와 예외(Exception) 등을 구현할 때도 사용될 수 있다.
일반 프로그래밍과 후속문 프로그래밍를 비교해보면서 마무리하겠다.
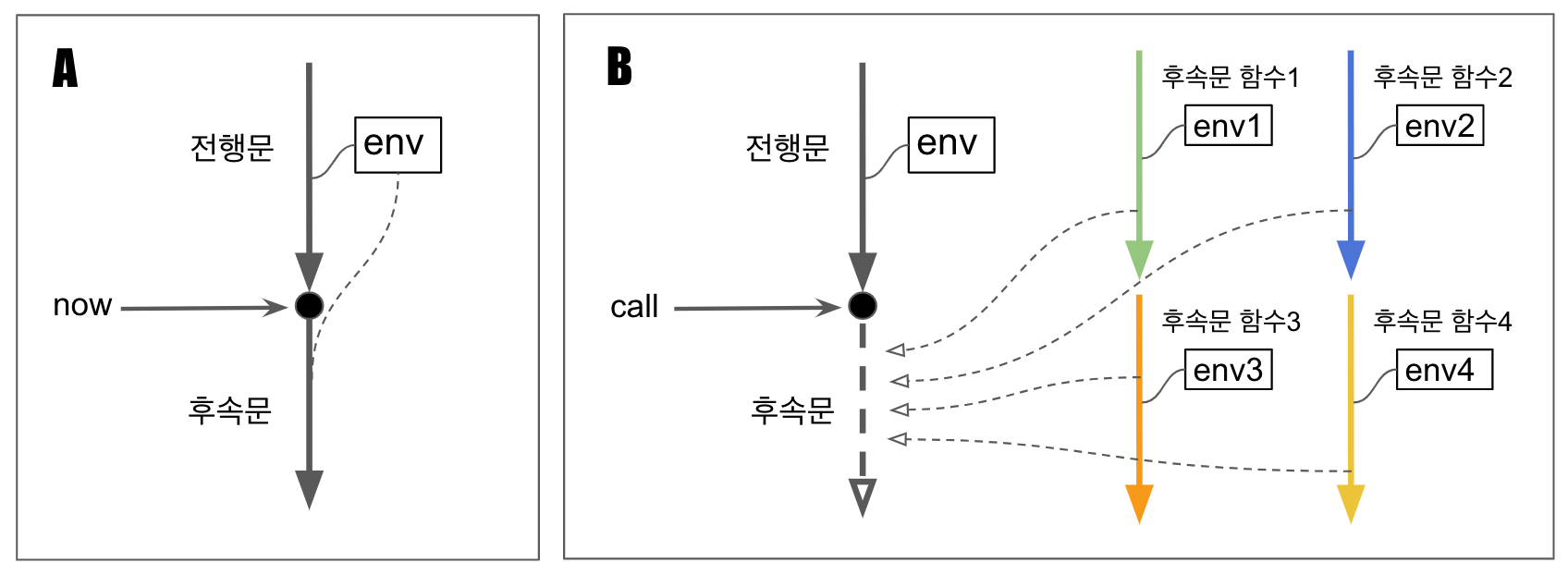
위 그림의 왼쪽 박스 A는 일반적인 프로그래밍을 나타낸다. 일반 프로그래밍에서 모든 프로그램은 현재 시점을 기준으로 그 이전은 전행문, 그 이후는 후속문으로 나눌 수 있다. 이때 후속문은 전행문과 스택 등의 실행 환경(위 그림에서는 evn 상자)을 공유한다. 일반 프로그래밍에서의 함수 호출도 사실은 스택을 공유하는 것이다. 다만 스택 프레임이 한 층 쌓일 뿐이다. 예외를 던지는 것은 같은 스택상의 스택 프레임을 벗어나는 것일 뿐이지, 결코 스택 자체를 벗어나는 것은 아니다.
반면 위 그림의 오른쪽 박스 B는 후속문 프로그래밍을 나타낸다. 여기서는 무엇이 후속문이 될지 결정되지 않았다. 그것을 결정하는 것은 어떤 후속문 함수를 호출하는가에 달렸다. 만약 위 그림에서 후속문 함수1이 호출되었다면, 전행문의 실행 환경은 버려지고 후속문은 자신의 실행환경을 가지고 실행된다. 이때 스택도 완전히 후속문 함수1의 스택으로 교체되는 것이다.